
Wikipedia:Indic transliteration
| This page documents an English Wikipedia content guideline. Editors should generally follow it, though exceptions may apply. Substantive edits to this page should reflect consensus. When in doubt, discuss first on this guideline's talk page. |
This is a guideline for the transliteration (or Romanization) of writings from Indic languages and Indic scripts for use in the English-language Wikipedia. It is based on ISO 15919, and is applicable to all languages of south Asia that are written in Indic scripts.
All transliteration should be from the written form in the original script of the original language of the name or term. The original text in the original script may also be included for reference and checking.
Formal transliteration
[edit]The formal transliteration may be used to accurately and unambiguously present the phonetic content of the original script. It should be provided for reference whenever reference to the original source is needed.
The scheme is based on ISO 15919 for Indic scripts. This is very close to IAST with minor differences to accommodate non-Devanagari scripts. The differences are:
- ए - IAST: e, ISO: ē
- ओ - IAST: o, ISO: ō
- अं - IAST: ṃ, ISO: ṁ (ṃ is used to specifically represent Gurmukhi Tippi ੰ)
- ऋ - IAST: ṛ, ISO: r̥
- ॠ - IAST: ṝ, ISO: r̥̄
Simplified transliteration
[edit]A set of simplified transliteration symbols is provided here. These are not part of the ISO standard. They have been devised for Wikipedia, and they may be used to avoid the use of diacritic marks. Simplified transliterations should not be considered to be authoritative, and may result in ambiguous transliteration.
Inherent vowel
[edit]When the source script does not indicate the removal of the inherent 'a' and it is not pronounced in the original source language, such unpronounced 'a's are removed.
The inherent vowel is always transliterated as 'a' in the formal ISO 15919 transliteration. In the simplified transliteration, 'a' is also normally used except in the Bengali, Assamese, and Odia languages, where 'o'/'ô' is used. See Romanization of Bengali for the transliteration scheme set for Bengali on Wikipedia.
In certain instances, the inherent vowel is not pronounced. The rules for such differ among languages. In some instances, the removal of an inherent vowel is explicitly marked by the presence of a virama.
| Devanagari | क् |
|---|---|
| Bengali | ক্ |
| Gurmukhi | ਕ੍ |
| Gujarati | ક્ |
| Oriya | କ୍ |
| Tamil | க் |
| Telugu | క్ |
| Kannada | ಕ್ |
| Malayalam | ക് |
| Sinhala | ක් |
Vowels
[edit]Vowels are presented in their independent form on the left of each column, and combined with the corresponding consonant ka on the right. An asterisk indicates that the letter or ligature exists, but has not been encoded in unicode or is archaic/obsolete.
| ISO 15919 | Simplified | IPA | Devanagari | Bengali/Assamese | Gurmukhi | Gujarati | Oriya | Tamil | Telugu | Kannada | Malayalam | Sinhala | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | a | ə/ɐ/ä/ɔ/o | अ | क | অ | ক | ਅ | ਕ | અ | ક | ଅ | କ | அ | க | అ | క | ಅ | ಕ | അ | ക | අ | ක |
| ā | a | aː/a | आ | का | আ | কা | ਆ | ਕਾ | આ | કા | ଆ | କା | ஆ | கா | ఆ | కా | ಆ | ಕಾ | ആ | കാ | ක | කා |
| æ | ae | æ | ऍ | कॅ | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | ඇ | කැ |
| ǣ | ae | æː | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | ඈ | කෑ |
| i | i | i | इ | कि | ই | কি | ਇ | ਕਿ | ઇ | કિ | ଇ | କି | இ | கி | ఇ | కి | ಇ | ಕಿ | ഇ | കി | ඉ | කි |
| ī | i | iː/i | ई | की | ঈ | কী | ਈ | ਕੀ | ઈ | કી | ଈ | କୀ | ஈ | கீ | ఈ | కీ | ಈ | ಕೀ | ഈ | കീ | ඊ | කී |
| u | u | u | उ | कु | উ | কু | ਉ | ਕੁ | ઉ | કુ | ଉ | କୁ | உ | கு | ఉ | కు | ಉ | ಕು | ഉ | കു | උ | කු |
| ū | u | uː/u | ऊ | कू | ঊ | কূ | ਊ | ਕੂ | ઊ | કૂ | ଊ | କୂ | ஊ | கூ | ఊ | కూ | ಊ | ಕೂ | ഊ | കൂ | ඌ | කූ |
| ĕ | e | æ/ɛ | ॲ | कॅ | - | - | - | - | ઍ | કૅ | - | - | - | - | - | - | - | - | - | - | - | - |
| e | e | e | ऎ | कॆ | - | - | - | - | - | - | - | - | எ | கெ | ఎ | కె | ಎ | ಕೆ | എ | കെ | එ | කෙ |
| ē | e | eː/e/ɛ | ए | के | এ | কে | ਏ | ਕੇ | એ | કે | ଏ | କେ | ஏ | கே | ఏ | కే | ಏ | ಕೇ | ഏ | കേ | ඒ | කේ |
| ai | ai | ɛː/əj/æ/ɔj/oj | ऐ | कै | ঐ | কৈ | ਐ | ਕੈ | ઐ | કૈ | ଐ | କୈ | ஐ | கை | ఐ | కై | ಐ | ಕೈ | ഐ | കൈ | ඓ | කෛ |
| ŏ | o | ɔ | ऑ | कॉ | - | - | - | - | ઑ | કૉ | - | - | - | - | - | - | - | - | - | - | - | - |
| o | o | o | ऒ | कॊ | - | - | - | - | - | - | - | - | ஒ | கொ | ఒ | కొ | ಒ | ಕೊ | ഒ | കൊ | ඔ | කො |
| ō | o | oː/o | ओ | को | ও | কো | ਓ | ਕੋ | ઓ | કો | ଓ | କୋ | ஓ | கோ | ఓ | కో | ಓ | ಕೋ | ഓ | കോ | ඕ | කෝ |
| au | au | ɔ/əw/ɔw/ow | औ | कौ | ঔ | কৌ | ਔ | ਕੌ | ઔ | કૌ | ଔ | କୌ | ஔ | கௌ | ఔ | కౌ | ಔ | ಕೌ | ഔ | കൌ | ඖ | කෞ |
| r̥ | ri | r̩/ri/ru | ऋ | कृ | ঋ | কৃ | - | - | ઋ | કૃ | ଋ | କୃ | - | - | ఋ | కృ | ಋ | ಕೃ | ഋ | കൃ | ඍ | කෘ |
| r̥̄ | ri | r̩ː/riː/ruː/ri/ru | ॠ | कॄ | ৠ | কৄ | - | - | ૠ | કૄ | ୠ | କୄ | - | - | ౠ | కౄ | ೠ | ಕೄ | ൠ | കൄ | ඎ | කෲ |
| l̥ | li | l̩/li/lu | ऌ | कॢ | ঌ | কৢ | - | - | ઌ | કૢ | ଌ | କୢ | - | - | ఌ | కౢ | ಌ | ಕೢ | ഌ | കൢ | ඏ | කෟ |
| l̥̄ | li | l̩ː/liː/luː/li/lu | ॡ | कॣ | ৡ | কৣ | - | - | ૡ | કૣ | ୡ | କୣ | - | - | ౡ | కౣ | ೡ | ಕೣ | ൡ | കൣ | ඐ | කෳ |
Consonants
[edit]See also Brahmic family#Consonants.
| ISO 15919 | Simplified | IPA | Devanagari | Bengali/ Assamese |
Gurmukhi | Gujarati | Oriya | Tamil | Telugu | Kannada | Malayalam | Sinhala |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k | k | k | क | ক | ਕ | ક | କ | க | క | ಕ | ക | ක |
| kh | kh | kʰ | ख | খ | ਖ | ખ | ଖ | கஃ | ఖ | ಖ | ഖ | ඛ |
| g | g | g | ग | গ | ਗ | ગ | ଗ | க | గ | ಗ | ഗ | ග |
| gh | gh | gʱ | घ | ঘ | ਘ[1] | ઘ | ଘ | கஃ | ఘ | ಘ | ഘ | ඝ |
| ṅ | n | ŋ | ङ | ঙ | ਙ | ઙ | ଙ | ங | ఙ | ಙ | ങ | ඞ |
| c | ch | ʧ/s | च | চ | ਚ | ચ | ଚ | ச | చ | ಚ | ച | ච |
| ch | chh | ʧʰ/s | छ | ছ | ਛ | છ | ଛ | சஃ | ఛ | ಛ | ഛ | ඡ |
| j | j | ʤ/z | ज | জ | ਜ | જ | ଜ | ஜ | జ | ಜ | ജ | ජ |
| jh | jh | ʤʱ/z | झ | ঝ | ਝ[2] | ઝ | ଝ | ஜஃ | ఝ | ಝ | ഝ | ඣ |
| ñ | n | ɲ/n/- | ञ | ঞ | ਞ | ઞ | ଞ | ஞ | ఞ | ಞ | ഞ | ඤ |
| ṭ | t | ʈ/t | ट | ট | ਟ | ટ | ଟ | ட | ట | ಟ | ട | ට |
| ṭh | th | ʈʰ/tʰ | ठ | ঠ | ਠ | ઠ | ଠ | டஃ | ఠ | ಠ | ഠ | ඨ |
| ḍ | d | ɖ/d | ड | ড | ਡ | ડ | ଡ | ட | డ | ಡ | ഡ | ඩ |
| ḍh | dh | ɖʱ/dʱ | ढ | ঢ | ਢ[3] | ઢ | ଢ | டஃ | ఢ | ಢ | ഢ | ඪ |
| ṇ | n | ɳ/n | ण | ণ | ਣ | ણ | ଣ | ண | ణ | ಣ | ണ | ණ |
| t | t | t̪/t | त | ত | ਤ | ત | ତ | த | త | ತ | ത | ත |
| th | th | t̪ʰ/tʰ | थ | থ | ਥ | થ | ଥ | தஃ | థ | ಥ | ഥ | ථ |
| d | d | d̪/d | द | দ | ਦ | દ | ଦ | த | ద | ದ | ദ | ද |
| dh | dh | d̪ʱ/dʱ | ध | ধ | ਧ[4] | ધ | ଧ | தஃ | ధ | ಧ | ധ | ධ |
| n | n | n̪/n[5] | न | ন | ਨ | ન | ନ | ந | న | ನ | ന | න |
| ṉ | n | n | ऩ | - | ਨ਼ | ન઼ | - | ன | - | - | ഩ | න.[6] |
| p | p | p | प | প | ਪ | પ | ପ | ப | ప | ಪ | പ | ප |
| ph | ph | pʰ/f | फ | ফ | ਫ | ફ | ଫ | பஃ | ఫ | ಫ | ഫ | ඵ |
| b | b | b | ब | ব | ਬ | બ | ବ | ப | బ | ಬ | ബ | බ |
| bh | bh | bʱ | भ | ভ | ਭ[7] | ભ | ଭ | பஃ | భ | ಭ | ഭ | භ |
| m | m | m | म | ম | ਮ | મ | ମ | ம | మ | ಮ | മ | ම |
| y | y | j/dʒ | य | য | ਯ | ય | ୟ | ய | య | ಯ | യ | ය |
| r | r | r/ɾ[8] | र | র/ৰ[9] | ਰ | ર | ର | ர | ర | ರ | ര | ර |
| ṟ | r | r | ऱ | - | ਰ਼ | ર઼ | - | ற | ఱ | ಱ | റ | ර.[10] |
| r̆[11] | r | r | र् | - | - | - | - | - | - | - | - | - |
| l | l | l | ल | ল | ਲ | લ | ଲ | ல | ల | ಲ | ല | ල |
| ḷ | l | ɭ | ळ | - | ਲ਼ | ળ | ଳ | ள | ళ | ಳ | ള | ළ |
| ḻ | l | ɻ | ऴ | - | - | ળ઼ | - | ழ | ఴ | ೞ | ഴ | ළ.[12] |
| v | v | ʋ/w[13] | व | ৱ[14] | ਵ | વ | ଵ | வ | వ | ವ | വ | ව |
| ś | sh | ɕ/s/ʃ/x | श | শ | ਸ਼ | શ | ଶ | ஶ[15] | శ | ಶ | ശ | ශ |
| ṣ | sh | ʂ/s/ʃ/x | ष | ষ | - | ષ | ଷ | ஷ | ష | ಷ | ഷ | ෂ |
| s | s | s/ʃ/x | स | স | ਸ | સ | ସ | ஸ | స | ಸ | സ | ස |
| h | h | ɦ | ह | হ | ਹ[16] | હ | ହ | ஹ | హ | ಹ | ഹ | හ |
| q | q | q | क़ | ক় | ਕ਼ | ક઼ | କ଼ | க̡ | - | - | - | - |
| ḵẖ | kh | x | ख़ | খ় | ਖ਼ | ખ઼ | ଖ଼ | - | - | - | - | - |
| ġ | g | ɣ | ग़ | গ় | ਗ਼ | ગ઼ | ଗ଼ | - | - | - | - | - |
| z | z | z | ज़ | জ় | ਜ਼ | જ઼ | ଜ଼ | ஃஜ | - | ಜ಼ | - | - |
| ṛ | r | ɽ | ड़ | ড় | ੜ | ડ઼ | ଡ଼ | - | - | - | - | - |
| ṛh | rh | ɽʱ | ढ़ | ঢ় | ੜ੍ਹ | ઢ઼ | ଢ଼ | - | - | - | - | - |
| f | f | f | फ़ | ফ় | ਫ਼ | ફ઼ | ଫ଼ | ஃப | - | ಫ಼ | ഫ | ෆ |
| ẏ | y | j/e | य़ | য় | ਯ਼ | ય઼ | ଯ | - | - | - | - | - |
| t̤ | t | t̪ | त़ | ত় | ਤ਼ | ત઼ | ତ଼ | - | - | - | - | - |
| s̤ | s | s | स़ | স় | - | સ઼ | ସ଼ | - | - | - | - | - |
| h̤ | h | ɦ | ह़ | হ় | ਹ਼ | હ઼ | ହ଼ | - | - | - | - | - |
| w | w | w | व़ | র[17] | ਵ਼ | વ઼ | ୱ | வ̡ | - | - | - | - |
| ṯ | t | t | - | - | - | - | - | ற | - | - | റ്റ[18] (ഺ) | - |
| - | khy | kʰj | - | ক্ষ[19] | - | - | - | - | - | - | - | - |
- ^ See special notes for Punjabi, specifically voiced aspirates.
- ^ In Indo-Aryan languages, this letter is theoretically pronounced as a dental nasal, but it is actually alveolar. In Tamil and Malayalam, it is a dental nasal and the alveolar nasal has a separate letter (ṉ: see note below).
- ^ This letter is obsolete. See the Malayalam language article for further details.
- ^ In languages that contrast two rhotic consonants, this is generally [ɾ]. In Indo-Aryan languages that do not make this distinction but have [ɾ] and [r] as allophones, the /r/ phoneme is generally pronounced [ɾ] when following a voiced consonant (although there are exceptions, such as the consonant j /ʤ/) and [r] in most other environments.
- ^ Use when the distinction between the reph and eyelash form of Ra is required; otherwise transliterate as 'r'.
- ^ Used when writing Tamil in Sinhala script.
- ^ Use র for Bengali and Manipuri, and ৰ for Assamese.
- ^ Assamese and Manipuri only.
- ^ May be pronounced 'w' in some languages.
- ^ Also the Tamil ligature SRI (ஶ்ரீ = ஶ்ரீ or, prior to Unicode 4.1, ஸ்ரீ = ஸ்ரீ) should be transliterated as śrī with ś, although srī may be also acceptable. See [20] and [21].
- ^ See special notes for Punjabi. Specifically 'ha'.
- ^
- ^ This is the symbol for the geminate consonant - the letter for the single [t],
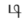 , has become obsolete.
, has become obsolete. - ^ Only in Assamese. ক্ষ in Assamese is not a composite but an individual letter with a phonetic value unlike in other languages.
Assamese velar fricatives
[edit]| ISO 15919 | Simplified | IPA | Assamese |
|---|---|---|---|
| ś | x | x | শ |
| ṣ | x | x | ষ |
| s | x | x | স |
Sinhalese half-nasals
[edit]| ISO 15919 | Simplified | IPA | Sinhala |
|---|---|---|---|
| n̆g | ng | ng | ඟ |
| jñ[22] | jn | gn | ඥ |
| n̆j | nj | nʤ | ඦ |
| n̆ḍ | nd | nɖ | ඬ |
| n̆d | nd | nd̪ | ඳ |
| m̆b | mb | mb | ඹ |
- ^ This character is technically a conjunct, but is encoded separately in Unicode.
Sindhi/Punjabi consonants
[edit]| ISO 15919 | Simplified | IPA | Devanagari | Gurmukhi | Shahmukhi | Saraiki |
|---|---|---|---|---|---|---|
| gg[23] | gg | ɠ | ॻ (ग॒) | ੱਗ | گّ | ڳ |
| jj[24] | jj | ʄ | ॼ (ज॒) | ੱਜ | جّ | ڄ |
| ḍḍ[25] | dd | ᶑ | ॾ (ड॒) | ੱਡ | ڈّ | ݙ |
| bb[26] | bb | ɓ | ॿ (ब॒) | ੱਬ | بّ | ٻ |
- ^ Represents Sindhi/Western Punjabi bbē (ٻ).
- ^ Represents Sindhi/Western Punjabi jjē (ڄ).
- ^ Represents Sindhi dd.ē (ڏ) or Western Punjabi dd.āl (ڋ).
- ^ Represents Sindhi ggē (ڳ) or Western Punjabi ggāf (ڰ).
Special notes for Punjabi
[edit]Punjabi is rather unique for an Indo-European language in that tones are a prominent feature of speech. As such, the IPA conversion is not accurate for Punjabi. Fortunately, there is a direct correlation between certain aspirated consonants and use of subscript /ha/ to represent different tones.
Voiced aspirates
[edit]The consonants that are employed for voiced aspirates in other Indian languages are not pronounced as such in Punjabi. In Punjabi these consonants are used to mark changes in tone. The table below indicates how each consonant is pronounced based on its position within a word.
| Consonant | Beginning of word | All other positions |
|---|---|---|
| ਘ | ਕ [k] |
ਗ [g] |
| ਝ | ਚ [ʧ] |
ਜ [ʤ] |
| ਢ | ਟ [ʈ] |
ਡ [ɖ] |
| ਧ | ਤ [t̪] |
ਦ [d̪] |
| ਭ | ਪ [p] |
ਬ [b] |
At the beginning or middle of a word, a voiced aspirate indicates a low tone on the following vowel. Examples:
- ਘੋੜਾ /gʱoːɽaː/ is actually pronounced [kòːɽaː]
- ਪਘਾਰਨਾ /pəgʱaːrnaː/ is actually pronounced [pəgàːrnaː]
- ਮਘਾਣਾ /məgʱaːɳaː/ is actually pronounced [məgàːɳaː]
At the end of the word (stem-final), the voiced aspirates indicate a high tone on the preceding vowel. Examples:
- ਕੁਝ /kuʤʱ/ is actually pronounced [kúʤ]
Ha
[edit]At the beginning of a word, ਹ indicates [ha].
In the middle or at the end of a word, ha indicates a high tone on the preceding vowel. Examples:
- ਚਾਹ [ʧaːh] is actually pronounced [ʧáː]
Subscript ha also indicates a high tone on the preceding vowel. Examples:
- ਪੜ੍ਹ [pəɽʱ] is actually pronounced [pə́ɽ]
The following conventions apply apart from at the beginning of a word:
- ਿਹ converts into a high tone ੇ (e.g. ਸਿਹਤ is pronounced ਸੇਤ [séːt̪]).
- 'ੁਹ converts into a high tone ੋ (e.g. ਸੁਹਣਾ is pronounced ਸੋਣਾ [sóːɳaː]).
- 'ਹਿ converts into a high tone ੈ (e.g. ਸ਼ਹਿਰ is pronounced ਸ਼ੈਰ [ɕǽr]).
- 'ਹੁ converts into a high tone ੌ (e.g. ਬਹੁਤ is pronounced ਬੌਤ [bɔ́t̪]).
References
[edit]- Teach Yourself Panjabi ISBN 0-07-143161-6 (p16, 19-21)
- [27]
- [28]
- [29]
Nasalisation
[edit]| ISO 15919 | IPA | Devanagari | Bengali | Gurmukhi | Gujarati | Oriya | Tamil | Telugu | Kannada | Malayalam | Sinhala |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ṁ[30] | ? | ं | ং | ਂ | ં | ଂ | ஂ | ం | ಂ | ം[31] | ං |
| ṃ[32] | ? | - | - | ੰ | - | - | - | - | - | - | - |
| m̐[33] | ? | ँ | ঁ | ਁ | ઁ | ଁ | - | - | - | - | - |
| n̆ | ? | - | - | - | - | - | - | ఁ | - | - | - |
- ^ The signs ṁ and ṃ are essentially identical. However, Gurmukhi has two separate nasal characters and if this distinction is to be retained separate identifiers must be used.
- ^ For Malayalam, it is transliterated as 'm' at the end of a word. There is no actual phonemic nasalisation in Malayalam. This symbol only indicates nasalisation when Malayalam script is being used to write Sanskrit. Otherwise, it represents either consonantal /m/ (without the inherent vowel) or consonantal /ŋ/ (without the inherent vowel), mostly in borrowed Sanskrit words that originally had nasalisation. Some of these borrowed words are pronounced with /m/ and others with /ŋ/, and, because of analogy, this symbol has come to represent these phonemes (when the vowels are suppressed - otherwise the normal letters would be used) in native words as well.
- ^ When applied to a semivowel (y, r, l, ḷ or v), in contrast to its application to a vowel, candrabindu is placed before the semivowel. For example, सय्ँयन्ता is written sa:m̐yyantā and not saym̐yantā.
The standard nasal signs (ṁ and ṃ) are only to be used at the end of words OR when it is crucial to keep the distinction between Bindi and Tippi use in Gurmukhi. Otherwise, the following rules should be enforced:
| When followed by | ISO 15919 | IPA |
|---|---|---|
| k, kh, g, gh or ṅ q, ḵẖ, or ġ |
ṅ | ŋ |
| c, ch, j, jh or ñ z |
ñ | ɲ |
| ṭ, ṭh, ḍ, ḍh, or ṇ | ṇ | ɳ |
| t, th, d dh, or n | n | n |
| p, ph, b bh, or m f |
m | m |
| y, r, l, v, ś, ṣ, s, h ẏ |
n | n |
References
[edit]- Transliteration of Non-Roman Scripts
- Transliteration of Indic scripts: How to use ISO 15919[dead link]
- Script specific resources
- The Sindhi Alphabet
- The Western Punjabi Alphabet
- Sinhala to International Phonetic Alphabet Transliteration Scheme
- Free Online Indic Transliteration in all Indian Languages and to image conversion Bengali - Hindi - Kannada - Malayalam - Oriya - Punjabi - Tamil - Gujarati - Punjabi\Gurumukhi & Telugu
- Online Transliteration/Transcription Tool
- Tamil Unicode Keyboard